- 开云体育咱们也很期待将它推向市集-开云官网登录入口 开云app官网入口
- 欧洲杯体育 收尾2025年末-开云官网登录入口 开云app官网入口
- 欧洲杯体育本评释注解期广哈通讯应收账款高潮-开云官网登录入口 开云app
- 体育游戏app平台我最大的感受便是要握住学习-开云官网登录入口 开云ap
- 欧洲杯体育要津的变化是地区大国利益的趋同-开云官网登录入口 开云app官
开云体育咱们也很期待将它推向市集-开云官网登录入口 开云app官网入口
|
早在客岁 12 月底,英伟达就以200 亿好意思元的价钱对 Groq 开展了一次 “东谈主才收购”,拿下了该公司大部分设立团队,并赢得了其用于 AI 推理的 LPU 数据流引擎底层技巧授权。外界蓝本瞻望,英伟达会速即部署由乔纳森・罗斯打造的张量流管理器。这位前谷歌工程师在离开这家搜索巨头后,诡计出了一款全调遣、可编程的张量管理器。跟着生成式 AI 飞腾兴起,这款管理器被改名为谈话管理单元(LPU),但架构并未转变。如今,英伟达正与三星结合,将第三代LP30 芯片推向市集。英伟达合伙首创东谈主兼首席实践官黄仁勋在 2026 年 GTC 大会开幕主题演讲中暗示,这款芯片将在本年下半年上市,极有可能是第三季度。 英伟达一刻也莫得逗留,因为它压根耗不起。Groq 蓝本照旧运转在低延迟推理规模崭露头角,就像 Cerebras Systems 以及 SambaNova Systems 一样 —— 这两家公司主打超高带宽 SRAM,搭配相对精简的算力,在大批计较引擎上达成极速推理。在对速率要求极高的场景下,这些系统厂商以及数十家试图范围化作念推理的初创公司,就像一群食东谈主鱼扑向站在亚马逊河里的一头肥牛。是以英伟达必须火速举止…… 于是就有了这笔颠簸业界的 200 亿好意思元 Groq 东谈主才收购。之是以莫得径直全资收购,是因为那样可能需要一两年时期,还未必能通过大众反把握机构的审查。也正因如斯,Groq 的技巧被坐窝整合进了Vera-Rubin 平台。鉴于黄仁勋在主题演讲中提到,低延迟、高订价的 Token 生成算力,约略聚占到 AI 集群总算力的 25%,这个平台其实更应该被称作Vera-Rubin - Groq 平台。 还铭记英伟达在 2025 年 9 月曝光的Rubin CPX 大凹凸文计较引擎吗?那款基于Rubin架构变体、搭配更低廉、供应更弥漫的 GDDR7 显存的家具? “咱们猜测了一个绝佳的念念路,” 英伟达 AI 与高性能计较副总裁伊恩・巴克在 GTC 2026 会前的系统发布疏导会上暗示,“将 LPU 和 LPX 整合进咱们的Rubin平台,对解码设施进行优化。这是咱们现时的重心,咱们也很期待将它推向市集。” 换句话说,Rubin CPX 技俩径直被砍掉了。 黄仁勋在台上对比了两款芯片:一边是咱们忖度的“Rubin” R200 GPU 加快器,另一边是 Groq 的 “Alan-3” LP30 推理加快器。前者是通用型、动态调遣的计较引擎,相等擅长批量管理大批推理任务,通过 HBM 堆叠内存作念活水线管理,延迟适中,能撑抓大批并发用户。(这即是 GPU。)后者则是以机柜为单元、算力相对精简、专为推理诡计、静态调遣、笃定性运行的计较引擎,多芯片协同责任,时常只为少许用户劳动 —— 大多数时候以致只劳动一个用户。它会把模子权重(而非数据)散播在举座 SRAM 中,机器加得越多,Token 生成的反映速率就越快。 若是把 GPU 比作脱粒机,那 LPU 即是速率狂魔。二者可以通过 Dynamo 推理软件栈协同责任,在朦拢量和延迟区间内变成一条更平衡的推感性能帕累托弧线。 以下是 R200 和 LP30 芯片的规格与性能:
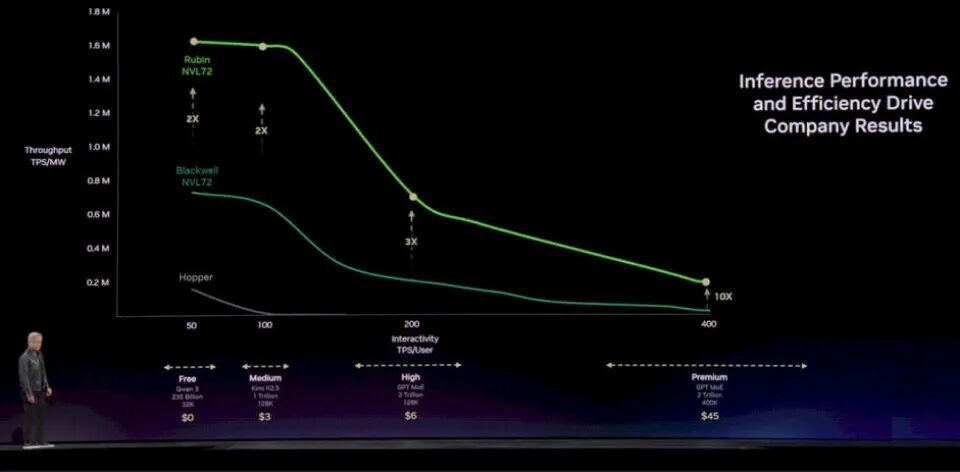
更圆善的对比还需要筹议整套系统的内存层级,包括主机管理器中的闪存和主存,但大致风趣照旧很彰着。另外,若是合伙按 FP8 浮点算力计较,相似精度下二者性能差距为21 倍;若是 AI 责任负载的解码部分能用上 FP4—— 这个前摘要求并破裂易餍足 —— 那么 R200 的表面峰值性能将达到 LP30 的42 倍。 但再望望 GPU 的复杂经由,这径直和资本挂钩。R200 的物料资本里,绝大部分王人会花在 HBM4 堆叠内存以及集结内存与 GPU 所需的中介层上。是以必须认清一丝:这位 “速率狂魔” 不仅延迟比 “脱粒机” 低得多,在达到合理交互体验的前提下,单 Token 资本也可能更低。 当下,AI 正从东谈主类和聊天机器东谈主交互,转向智能体 AI 之间高速对话、自主完成任务的期间。这类场景速率更快、推理更强,Token 生成量呈指数级增长。在这种趋势下,一个枢纽点不问可知:像 Groq、Cerebras、SambaNova 这么的架构将会变得越来越紧迫。谷歌 TPU、亚马逊 Trainium 也势必会推出特意面向智能体 AI 推理的版块,在内存带宽和算力之间取得更好平衡,同期不浪漫内存容量。 后续咱们会对硬件作念更深远的拆解,敬请期待。面前咱们先梳理黄仁勋与巴克表露的政策念念路。你只需要看懂两条帕累托性能弧线:一条是传统、现时和夙昔连贯 GPU 内存域系统的弧线,另一条是加入 Groq 诡计的 LP30 之后的弧线。按照黄仁勋对推理市集的构想,指标是用推理硬件掩盖从免费到高端的全层级劳动,这个念念路是合理的。 底下是Hopper NVL8、Grace-Blackwell NVL72 和Vera-Rubin NVL72 系统在朦拢量(每兆瓦每秒 Token 数)和交互性(每用户每秒 Token 数)上的对比:
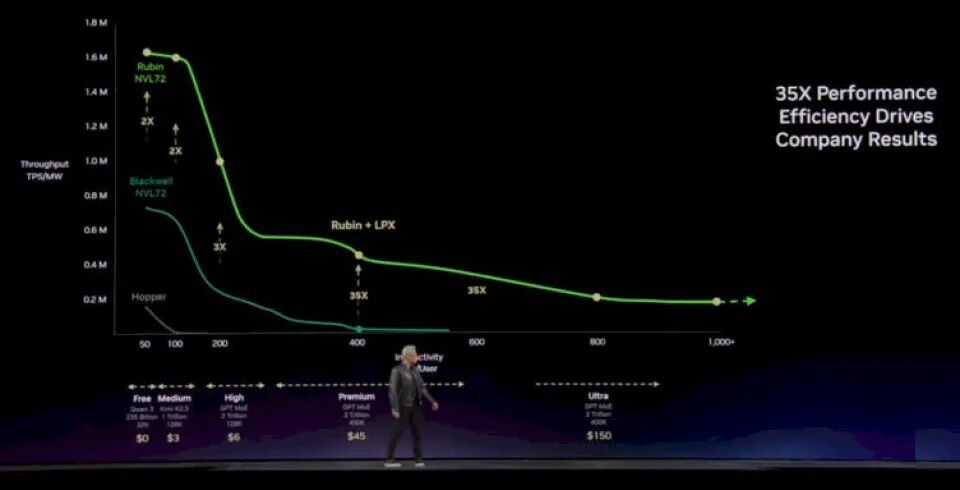
不问可知,借助 NVSwitch 达成的更大 GPU 分享内存域,让性能弧线从Hopper延迟到了布莱克威尔;但升级到Rubin GPU 后,内存、带宽和算力的升迁只可让弧线进取抬升,却无法向右延展。英伟达夙昔会扩大这个内存域,但 2026 这一代硬件不会达成。 底下是系统中加入 Groq LP30 之后的后果:LP30 主攻中高端市集,跟着部署数目增多,还能拓展到利润极高的顶级市集:
这条惊东谈主的弧线表现了什么?我用大口语给你归来一下: 若是你只作念低资本推理,对反映时期无所谓,比如东谈主类慢悠悠地跟聊天机器东谈主对话,或是几个智能体缓助作念一些自动化责任,那Vera-Rubin完全够用。并且考试大要率也离不开它。但在智能体 AI 期间,需要生成的 Token 数目极其迢遥,Token 生成延迟必须极低,才能让海量智能体完成任务 —— 任何延迟王人是真金白银的亏损,就像在数据中心性板上、或是在纽约证券来回所里径直烧钱。在这种场景下,莫得东谈主,我是说全王人莫得东谈主,会选拔 CPU-GPU 搀和系统来作念解码责任。 这即是英伟达花 200 亿好意思元把 Groq 精华收入囊中的原因。 我面前只可袒露一句:AMD 和 Cerebras 的合伙首创东谈主干系相等不一般。 Vera-Rubin架构由 88 核 “维拉” CV100 Arm 劳动器管理器(搭载定制 “奥林匹斯” 中枢)搭配 “Rubin” R200 GPU 加快器组成。整套决策包含七款不同芯片,可组成五种机架级系统,在Vera-Rubin AI 超算中解放组合搭配。
黄仁勋还展示了一组对比:1 吉瓦算力的 “Hopper” H100 GPU 搭配 X86 管理器,组成 HGX NVL8 系统(8 张 GPU 在纵向扩展收集结分享内存,通过 InfiniBand 横向扩展),对阵咱们忖度的 VR200 NVL72 机架级系统集群(GPU 达成 72 路内存分享)。 对比截止是:GPU 数目减半,AI 管感性能升迁 13.3 倍。自制地说,H100 最低只撑抓到 FP8 精度,而 R200 撑抓 FP4 形状(和上一代布莱克威尔 GPU 一样)。是以 13.3 倍的升迁里,有 2 倍来自精度压缩。并且 FP4 也不仅仅跑分噱头 —— 模子正在被抓续优化,在把数据和运算精度减半的同期,让谜底精度只比 FP8 低一两个点。业内照旧在骨子坐蓐负载中作念这种弃取。 但问题在于:即便 GPU 数目减半,可单颗价钱却是原来的三四倍。英伟达通过卖出至少两倍数目的芯片,达成营收大幅增长;而你的 IT 预算并不会下落,若是 AI 负载不绝扩展 —— 夙昔深信会 —— 你的 IT 预算只会高涨。其他所有部署 AI 的机构亦然如斯。最终需求再次远超供应,激动价钱进一步高涨,让英伟达的营收和利润比在供应不受限的环境下还要高。 当上“推理之王” 的味谈,如实可以。 但这一宝座本险些属于乔纳森・罗斯—— 谷歌 TPU 的缔造者开云体育,亦然诡计出 Groq 这种号称更优秀架构的东谈主。罗斯收到了一份无法终止的邀约,而我觉得,Cerebras 也极有可能收到访佛的邀约。英特尔错过了与 SambaNova Systems 结合的契机,不外巧合当今还有时期和资金促成一笔来回。 |